Por que aprender estatística?
Por que aprender Estatística
É comum vermos a aversão de estudantes de ciência da computação quando falamos das matérias de pura matemática (nossas queridas geometria analítica e cálculo). A estatística pode ser vista da mesma maneira por muitos, porém a aversão de agora pode se transformar em grande interesse no futuro.
Quando pensamos em estatística, já pensamos em porcentagem e médias — coisas que são vistas no ensino antes da faculdade. É claro que esse tipo de conhecimento é utilizado na vida do programador, bem como no cotidiano de qualquer pessoa.
Agora, para nós, programadores, é importante ir além desse conhecimento básico de estatística, utilizando os diversos recursos estatísticos para buscar um olhar diferente para os nossos problemas.
No mundo globalizado que vivemos, a geração de dados é constante, e as grandes corporações trabalham arduamente na coleta de dados, a partir dos quais se obtém o precioso ganho de informação. Como diria Clive Humby: “Data is the new oil” (os dados são o novo petróleo).
É a partir da junção do conhecimento estatístico e dos poderes da computação e seus algoritmos que surge a ciência de dados.
O que é ciência de dados
Segundo a AWS (gigantesca empresa de computação em nuvem da Amazon), a ciência de dados é o estudo de dados em busca de conhecimento para negócios, sendo uma área interdisciplinar entre matemática, estatística, inteligência artificial e engenharia da computação voltada a dados.
Hoje, a ciência de dados envolve vários processos e se torna necessário especialistas em cada processo (o que muitas vezes são confundidos como o mesmo cargo).
Engenheiro de dados, Cientista de dados e Analista de dados
Não, eles não são a mesma pessoa. O engenheiro de dados se especializa em preparar os dados, trabalhando com banco de dados e ferramentas de big data.
O Cientista de dados, apesar de ter a capacidade de realizar praticamente todo o pipeline da manipulação de dados, foca em gerenciar modelos de aprendizado de máquina para “criar” a informação que esses dados apresentam.
Já o analista de dados faz a análise e interpretação dos resultados, criando visualizações adequadas do conhecimento e auxiliando na tomada de decisão da empresa.
Os processos da ciência de dados
Fica mais fácil entender a separação dos especialistas, bem como a própria ciência de dados, com o detalhamento dos passos realizados nesta área:
1. Identificação do Problema
Antes de aplicar os conhecimentos estatísticos e computacionais, o primeiro passo vai ser entender o problema, saber o contexto que está inserido, assim facilitando metas, organização de dados e visualização dos resultados posteriormente. É interessante, quando possível, ter um especialista no contexto do problema, para assim facilitar o processo de entendimento da problemática, otimizando o tempo da equipe.
2. Mineração de dados
Nessa fase é a hora de pegarmos as picaretas e irmos para a caverna (brincadeira…, mas quase isso), nesse momento ocorre a coleta dos dados, que podem ser de diversas fontes, exigindo um conhecimento em banco de dados, scrapping e tudo que possa ajudar na coleta de dados.
3. Limpeza de dados
Agora o que foi coletado vai receber o tratamento para eliminar os ruídos, dados faltantes, inconsistentes e/ou duplicados. Em alguns casos vai ser necessário a padronização dos tipos dos dados, até mesmo sua normalização. Casos de falta significativa de dados podem ser resolvidos a partir de inserção de dados artificiais, onde existem inúmeras técnicas para a imputação desses dados.
4. Exploração dos dados
Na Exploração dos dados é feita a análise para entender o que foi produzido a partir de todos esses processos, gerando um conhecimento inicial de como trabalhar com esses dados. Essa fase é apoiada em métodos estatísticos e de visualização de dados para melhor compreensão da base de dados.
5. Engenharia de Atributos
Agora sabendo mais sobre os dados constituídos, podemos relacioná-los e até mesmo criar novos para adicionar mais valor à nossa base. Informações que antes não estavam claras e relacionadas, agora com uma maior clareza e padronização são encontradas, e dessa forma temos a possibilidade de criar mais dados aumentando o potencial ganho de conhecimento no final de todo o processo.
6. Modelos de Aprendizagem de Máquina
Já prepare seu Python e/ou R, pois aqui aplicamos os mais diversos algoritmos de aprendizagem de máquina. Importante ter o domínio desses algoritmos, para entender qual se encaixaria melhor com o problema, bem como trabalhar com seus parâmetros a fim de otimizar os resultados do seu algoritmo.
Apesar de parecer só um momento computacional, vai ser necessária a análise estatística dos modelos criados, são os mais diversos mecanismos estatísticos utilizados a fim de comprovar o real valor do seu modelo, desde análise de significância entre os modelos criados, até mesmo a simples acurácia de predição, ou a completude de um agrupamento, são várias as ferramentas que a nossa querida estatística pode proporcionar.
7. Visualização de dados
Chegou o momento de apreciar todo o suor gasto. O que para você parece uma obra-prima, o seu gerente não está entendendo nada, é nesse momento que é imprescritível ter bons gráficos e tabelas, que façam que as partes interessadas consigam entender o conhecimento gerado pelas etapas anteriores.
Conhecimentos que você precisa ter
Bom, por onde começar? Vamos listar alguns conhecimentos para começar sua jornada estatística.
Média, Mediana e Moda
Começando bem pelo começo, os 3Ms (não, não somos os 4Ms), a média nada mais é que a soma dos valores, dividida pela quantidade de valores. Por exemplo, se eu tiver os valores: 3, 2 e 4, eu tenho 3 valores:
2 + 4 + 3 = 9
9 / 3 = 3
Nossa média é 3
A mediana representa o valor central de uma distribuição de valores, é o termo central de uma lista de números. Na imagem abaixo fica mais simples de entender:
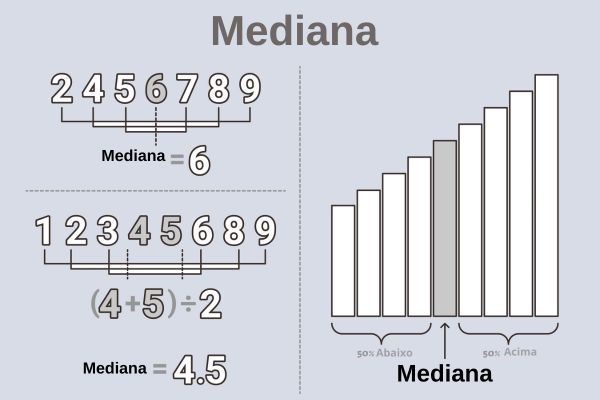
Fonte: Brasil Escola
Por fim a moda é o que vemos no cotidiano, o elemento que mais aparece está na moda, no caso da estatística a lógica é a mesma, num conjunto de números, o que mais aparece é a moda dessa distribuição. Temos um exemplo abaixo:
1, 2, 3, 4, 5, 6, 7, 7, 7, 8, 8, 9, 10.
A moda é o número 7.
Variância e Desvio Padrão
A variância está relacionada com a variação entre os dados em relação à média. Podemos ter variância populacional (com todos os elementos da população) ou variância amostral (com um grupo da população).
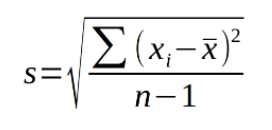
Fonte: Link para a Imagem
Caso queira calcular a variância populacional, basta retirar o “n-1” e dividir por “n”.
O desvio padrão informa o quão o conjunto de dados é uniforme. Quanto menor o valor, mais próximos os dados são entre si, e quanto maior, mais heterogêneos.
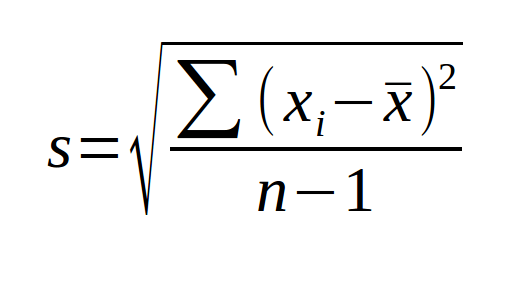
Fonte: Calcular e Converter
Tipo de Variáveis (Estatística Descritiva)
Então agora vamos usar inteiros, floats e strings? Calma lá garotinho, não é bem assim. As variáveis na estatística se organizam de maneira um pouco diferente, primeiramente podemos dividi-las em quantitativas e qualitativas.
As variáveis quantitativas são a respeito de variáveis com valores numéricos, de caráter discreto ou contínuo. Nas variáveis discretas podemos relacionar com o tipo inteiro, tratando de casos como: número de filhos, número de casas, número de entregas, etc. (afinal de contas ninguém tem um filho e meio… eu acho). Já as contínuas como você deve estar imaginando, tratam de intervalos contínuos, alturas, pesos e tudo que podemos representar com números quebrados (nosso querido float/double é uma boa alusão).
As variáveis qualitativas tratam de variáveis que se relacionam com strings, assim como a quantitativa se separa em duas. As qualitativas nominais, são qualidades especificas, sem alguma ordem (spoiler da proxima), são variaveis como sexo, religião, profissão, etc. Para representar ordem são utilizadas as ordinais, são informações que esboçam uma sequência, uma ordem: nível de escolaridade (ensino fundamental, ensino médio, ensino superior), classe social, fase de algum processo e por aí vai.
Teste de Hipótese
A estatística é composta de vários testes e avaliações, separei o teste de hipótese por ser um bom pontapé inicial para sua jornada. Esse teste utiliza dados amostrais para criar hipóteses e gerar informação. Dado uma hipótese inicial esse teste tenta confirmar ou rejeitar essa hipótese, assim aceitando a hipótese complementar a ela (chamamos a primeira hipótese de H0 e a sua complementar como H1).
Vamos apresentar um exemplo para você compreender melhor: Vamos supor que você tem uma loja de eletrônicos, e você comprou uma remessa de mouses, esses mouses segundo o fornecedor demoram 2 anos para dar algum problema nele, mas você desconfia dessa informação e vai usar a estatística para ver se é verdade mesmo.
Sua primeira hipótese (Hipótese Nula/ H0) é que a vida útil é 2 anos, vamos considerar 730 dias
Sua segunda hipótese (Hipótese Alternativa/H1) é que a vida útil é menor que esses 2 anos.
Então você vendeu 40 mouses e depois de um tempo os clientes retornaram o feedback de quando o mouse apresentou o problema, com uma média de 700 dias e um desvio padrão de 50 dias.
Em um nível de significância de 5% o resultado do nosso teste é que sim, o fornecedor te passou a perna, a vida útil dos mouses é estatisticamente menor que 2 anos.
Avaliação Estatística
Você já deve ter ouvido falar que algo tem uma grande precisão, ou até mesmo na pandemia notícias com verdadeiros-positivos, falsos-positivos e se perguntando, como chegaram nesses números, bom agora você vai saber.
As avaliações estatísticas são índices que avaliam os resultados obtidos, além de simplesmente o número de saída de um algoritmo ou conta. A nossa simples precisão pode nos mostrar o quanto de acerto está ocorrendo dado um cenário, por exemplo, se você acertar 4 questões de 10 em uma prova de estatística - parabéns você precisa estudar mais - você tem uma precisão de 40% nessa prova.
Similar a precisão existe a acurácia (muito utilizada em algoritmos de aprendizagem de máquina), essa identifica o quanto os valores propostos em uma medição, predição ou outros métodos, estão próximos aos valores reais, imagine que seu algoritmo milagroso para predizer a reprovação em cálculo previu que 30 alunos da turma iriam reprovar - nem a máquina tem mais fé em vocês… - mas no final do ano vocês deram orgulho para quem acreditou em vocês e só 1 reprovou, a acurácia do seu modelo vai ser 27,5%, pelo menos vocês foram bem, diferente do seu modelo.
Em modelos de aprendizagem de máquina podemos trabalhar com diversas classes, onde a acurácia pode não representar exatamente como cada classe está sendo predita. Para trabalhar com classes é comum o uso de sensibilidade e especificidade.
A sensibilidade é a probabilidade de o modelo dizer que uma instância é da classe X, dentro de todas as instâncias que realmente são da classe X. A especificidade é a probabilidade do modelo dizer que a instância não participa da classe X, quando ela realmente não participa dessa classe. Um pouco confuso? Nesse exemplo você vai entender melhor a ideia desse tipo de avaliação:
Voltando para a loja de eletrônicos, você está avaliando se os teclados que vem para a equipe de manutenção tem algum problema ou não, para isso sua equipe alimenta um modelo com as informações do teclado e classifica-os em duas classes: defeituoso e zero-bala.
Para melhor apresentar os dados, podemos montar uma matriz de confusão. Essa matriz estabelece a relação entre predição e realidade, são 4 categorias que essa matriz compõe:
Verdadeiro-Positivo: Quando a predição acerta a classe positiva da instância (entenda como positiva a classe que quer ser predita pelo modelo, e não a classe que tem significado bom), e essa instância na realidade pertence a essa classe.
Falso-Positivo: Quando a predição acerta na classe positiva, mas na realidade a instância não pertence a essa classe.
Verdadeiro-Negativo: Quando a predição acerta na classe negativa (a outra classe do problema) e realmente a instância pertence a classe negativa.
Falso-Negativo: Quando a predição acerta na classe negativa, e na verdade ela pertence a classe positiva.
Voltando então para a matriz de confusão, imagine esse cenário:
| Real / Predito | Predito: Defeituoso | Predito: Zero-bala |
|---|---|---|
| Real: Defeituoso | 40 (VP) | 10 (FN) |
| Real: Zero-bala | 5 (FP) | 45 (VN) |
A sensibilidade será os Verdadeiros-Positivos (VP) dividido pela soma de Verdadeiros-Positivos mais os Falso-Negativo (FN).
40 / 40 + 10 = 40 / 50 = 0,8 ou 80%
Isso significa que o modelo detecta 80% dos teclados defeituosos.
Já a especificidade será os Verdadeiros-Negativos (VN) dividido pela soma de Verdadeiros-Negativos mais os Falsos-Positivos (FP).
45 / 45 + 5 = 45/50 = 0,9 ou 90%
Isso significa que o modelo detecta corretamente 90% dos teclados que não são defeituosos.
Conclusões finais
Depois de tantos números e informações, você conseguiu ter uma ideia de como a estatística é importante para a vida de um programador, desde de tratamento de dados a modelos de aprendizado de máquina, você deve estar preparado para aplicar seus métodos e conceitos, e esse é só o começo! Existem ainda muito mais recursos que podem ser aplicados, então não pare por aqui. Minha predição final é que você tem 50% de chance de ter gostado desse material - afinal de contas ou tu gosta ou não gosta - brincadeiras à parte, espero ter ajudado a dar uma chance para esse mundo.